语言模型处理文本时会将其分成小块,称为词元。为了理解自然语言,语言模型需要将词元转换为数值表示,即嵌入向量。
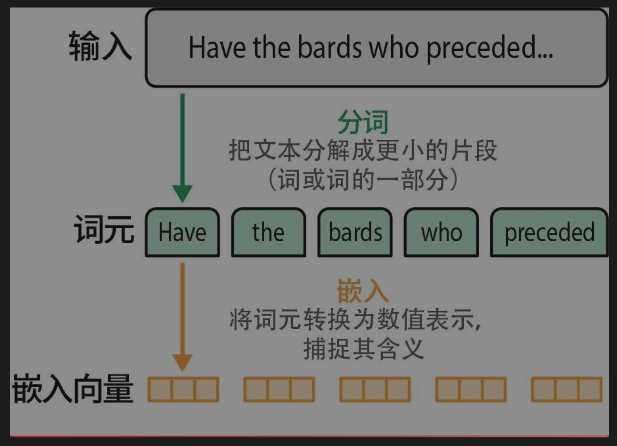
本章我们将深入探讨词元的本质以及LLM使用的分词方法。然后,我们将探讨著名的word2vec嵌入方法,它是现代LLM的先驱。我们将了解word2vec如何扩展词元嵌入(token embedding)的概念,来构建商业推荐系统,我们使用的许多互联网应用都是由推荐系统支持的。最后,我们将从词元嵌入过渡到句子或文本嵌入,即整个句子或文档可以用一个向量来表示
Q: 读书疑问❓我有些不理解为什么分词器要为所有词元分配一个索引,而不是直接使用utf-8等类似的编码中已经分配好的编码呢?这样不是更标准吗
A: 答案是为了效率和语义。
计算效率与序列长度:
- UTF-8/字符级粒度:一个汉字在UTF-8中通常占3个字节。一句话“你好,世界!”(6个字符)会被转换成至少6个输入单元。
- 子词级粒度(现代分词器):同一个句子可能被分词为
['你', '好', ',', '世界', '!'],共5个tokens。多语言支持与平衡
词汇表是精心设计的平衡体。
- 它的容量是固定的(例如5万、10万个词元)。
- 设计者需要在这有限的“座位”中,为不同语言、不同领域的词汇合理分配名额。
- 如果直接用UTF-8,就无法控制这种平衡。一些常用词(如
"the")和非常生僻的汉字会占用相同的“权重”,这是极其低效的。自定义词汇表可以确保高频词、重要词拥有独立的、快速的索引,而生僻字则可能被归入<unk>(未知词)或用子词拆分。
扩展:
文本表示的目的是将人类语言的自然形式转化为计算机可以处理的形式,也就是将文本数据数字化,使计算机能够对文本进行有效的分析和处理。
在 NLP 中,文本表示涉及到将文本中的语言单位(如字、词、短语、句子等)以及它们之间的关系和结构信息转换为计算机能够理解和操作的形式,例如向量、矩阵或其他数据结构。这样的表示不仅需要保留足够的语义信息,还需要考虑计算效率和存储效率。
四种类型分词方法:
- 子词级:最常用的分词方法
- 词级分词:在早期的word2vec等模型中很常见,但在NLP中的使用越来越少。词级分词的一个挑战是,分词器可能无法处理分词器训练完成之后才出现在数据集中的新词。这也导致词表中存在大量仅有细微差别的词元(如apology、apologize、apologetic、apologist)。
- 字符级分词:它仅仅依赖最原始的字母。虽然这使得分词更容易,但建模却变得更困难。
- 字节级分词:将词元分解为表示unicode(统一码)字符的单个字节。字节级分词是一种颇具竞争力的方法,尤其是在多语言场景中。
- 某些子词分词器也会在其词表中将字节作为词元,在遇到无法用其他方式表示的字符时,这是最终备选方案,例如GPT-2和RoBERTa分词器就是这样做的。
不同的分词模型对同一段文字分词结果的比较

出于不同的设计要求,有些模型对于代码的处理较好(StarCoder2(2024)、有些模型对科学知识领域较好(Galactica模型)
三大类设计上的选择决定了分词器如何分解文本:分词方法、用于初始化分词器的参数以及训练分词器的目标数据所在的领域。
- 分词方法
- 用于初始化分词器的参数
- 训练数据的领域
分词方法:BPE