感知机
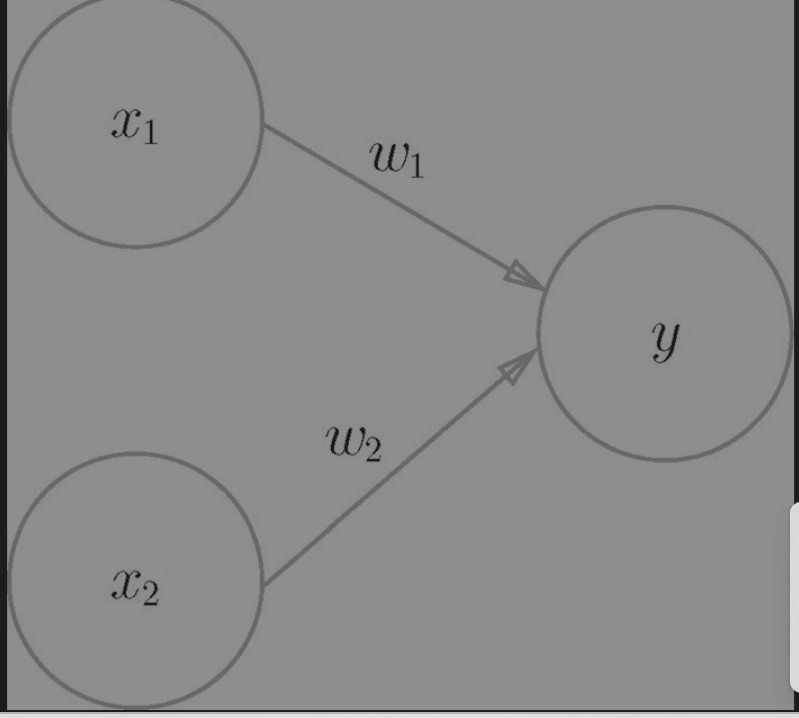
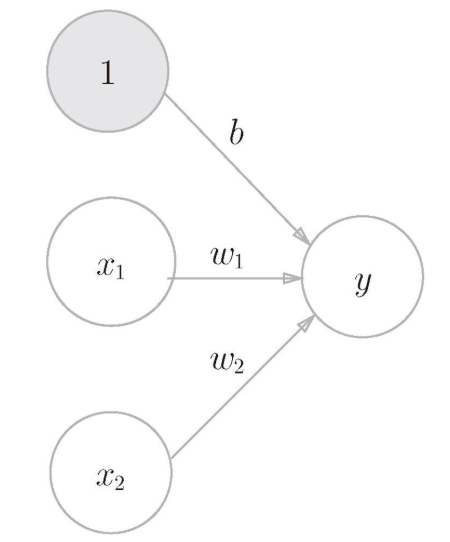
下图就是一个感知机:圆圈表示神经元,x1、x2 是输入信号,w1 和 w2 是权重,输入信号被送往神经元时,会乘以相应的权重,神经元会计算传送过来的信号的总和,只有当这个总和超过了某个界限值时,才会输出1。这也称为“神经元被激活”。这里将这个界限值称为阈值,用符号θ表示。
这里很像电流流经电阻,w 表示电阻
用数学公式表示:
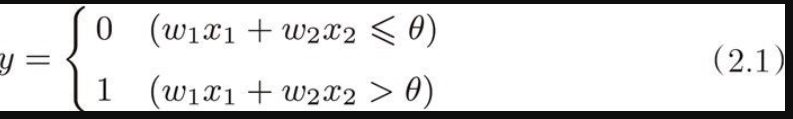
神经网络
激活函数
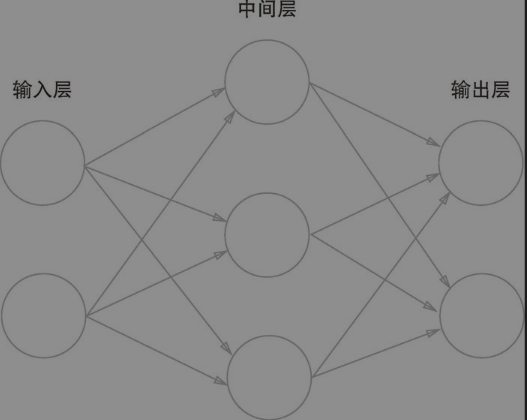
感知机的数学公式:
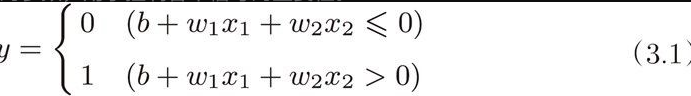
b是被称为偏置的参数,用于控制神经元被激活的容易程度;而 w1 和 w2 是表示各个信号的权重的参数,用于控制各个信号的重要性
可以将 3.1 简化,写作:
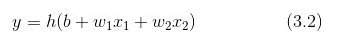
其中 h(x)函数也叫做激活函数:

上式中函数以阈值为界,一旦输入超过阈值,就切换输出。这样的函数称为“阶跃函数”。
- sigmoid 函数
神经网络中经常使用的一个激活函数是 sigmoid函数(sigmoid function):
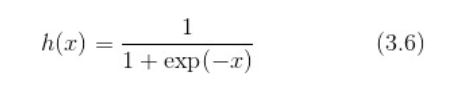
函数图形如下:
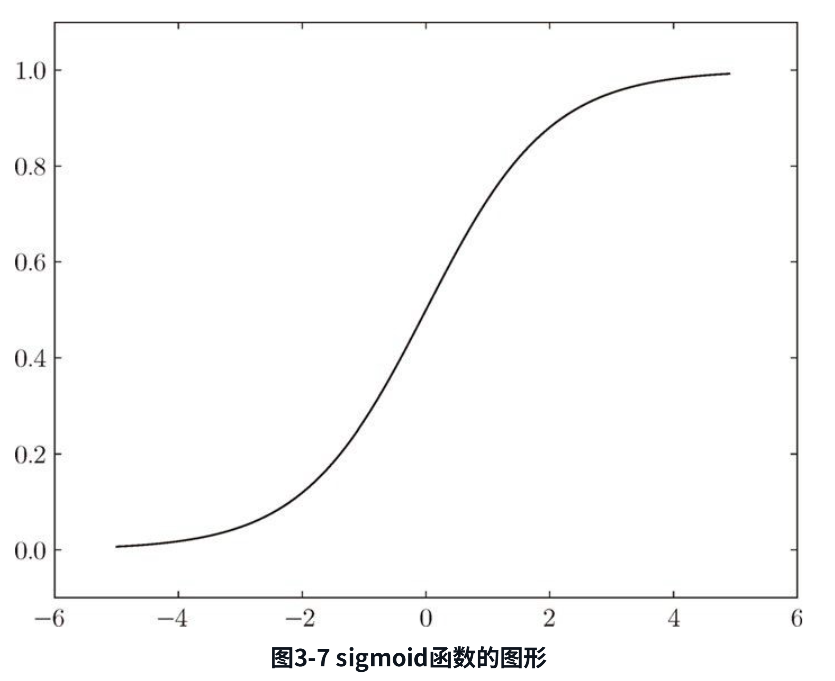
阶跃函数与 sigmoid 函数的区别:
- sigmoid函数是一条平滑的曲线,输出随着输入发生连续性的变化。而阶跃函数以0为界,输出发生急剧性的变化。sigmoid函数的平滑性对神经网络的学习具有重要意义。
阶跃函数与 sigmoid 函数的共同点:
- 当输入信号为重要信息时,阶跃函数和sigmoid函数都会输出较大的值;当输入信号为不重要的信息时,两者都输出较小的值。
- 不管输入信号有多小,或者有多大,输出信号的值都在0到1之间。
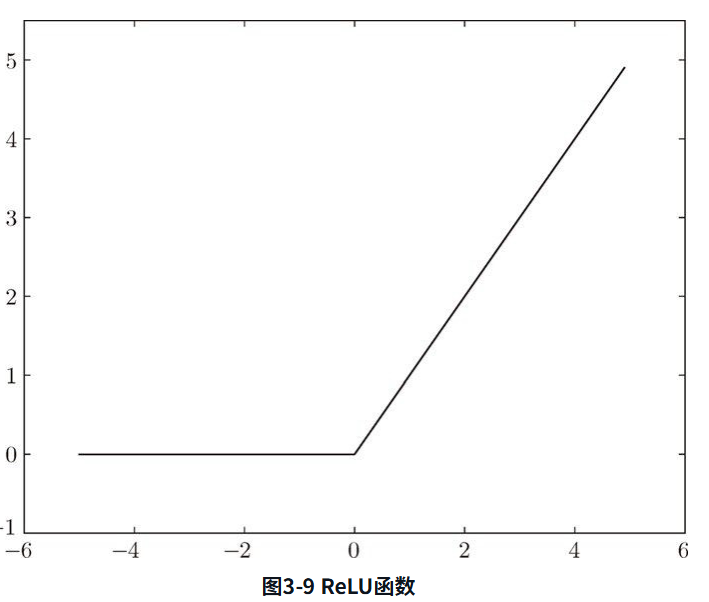
ReLU 函数
在神经网络发展的历史上,sigmoid函数很早就开始被使用了,而最近则主要使用ReLU(Rectified Linear Unit)函数。
ReLU函数在输入大于0时,直接输出该值;在输入小于等于0时,输出0。

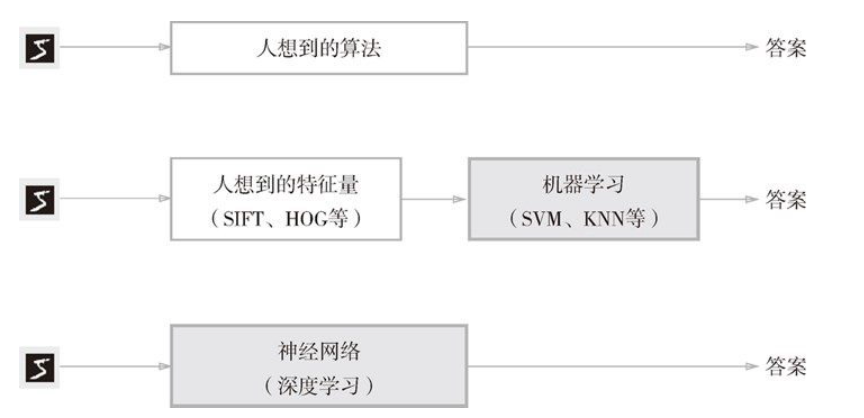
三层神经网络的实现
- 三层神经网络的实现
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def identity_function(x):
return x
def init_network():
network = {}
network['W1'] = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['W2'] = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
network['b2'] = np.array([0.1, 0.2])
network['W3'] = np.array([[0.1, 0.3], [0.2, 0.4]])
network['b3'] = np.array([0.1, 0.2])
return network
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = identity_function(a3)
return y
network = init_network()
x = np.array([1.0, 0.5])
y = forward(network, x)
print(y) # [ 0.31682708 0.69627909]init_network()函数会进行权重和偏置的初始化,并将它们保存在字典变量network中。这个字典变量network中保存了每一层所需的参数(权重和偏置)。forward()函数中则封装了将输入信号转换为输出信号的处理过程。
输出层的设计
机器学习的问题大致可以分为分类问题和回归问题。分类问题是数据属于哪一个类别的问题。比如,区分图像中的人是男性还是女性的问题就是分类问题。而回归问题是根据某个输入预测一个(连续的)数值的问题。比如,根据一个人的图像预测这个人的体重的问题就是回归问题(类似“57.4kg”这样的预测)。
四、神经网络的学习
为了评价训练的神经网络的性能,引入了损失函数这个指标。
以这个损失函数为基准,找出使它的值达到最小的权重参数,就是神经网络学习的目标。
为了找到尽可能小的损失函数值,使用函数斜率的梯度法。
机器学习中,一般将数据分为训练数据和测试数据两部分来进行学习和实验等。
使用训练数据进行学习,寻找最优的参数;然后,使用测试数据评价训练得到的模型的实际能力。
损失函数
损失函数是表示神经网络性能的“恶劣程度”的指标,即当前的神经网络对监督数据在多大程度上不拟合,在多大程度上不一致。
损失函数但一般用均方误差和交叉熵误差等。
均方误差公式如下 :
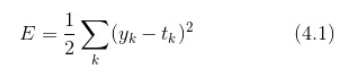
这里,yk 是表示神经网络的输出,tk 表示监督数据,k表示数据的维数。
交叉熵误差(cross entropy error)也经常被用作损失函数。交叉熵误差如下式所示:
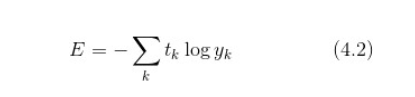
数值微分
numerical differentiation
导数就是表示某个瞬间的变化量,他可以定义为:
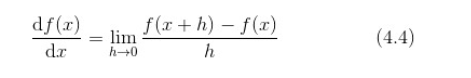
利用微小的差分求导数的过程称为数值微分(numerical differentiation)。而基于数学式的推导求导数的过程,则用“**解析性”(analytic)**一词,称为“**解析性求解”**或者“解析性求导”。比如,$ y = x^2 $的导数,可以通过$ \frac{\mathrm{d} y}{\mathrm{d} x}=2x $解析性地求解出来。因此,当x= 2时,y的导数为4。解析性求导得到的导数是不含误差的“真的导数”。
偏导数:有多个变量的函数的导数称为偏导数。
偏导数和单变量的导数一样,都是求某个地方的斜率。不过,偏导数需要将多个变量中的某一个变量定为目标变量,并将其他变量固定为某个值。
比如对于这个函数:
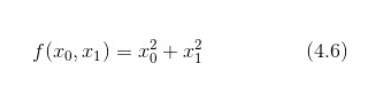
函数的图像如下:
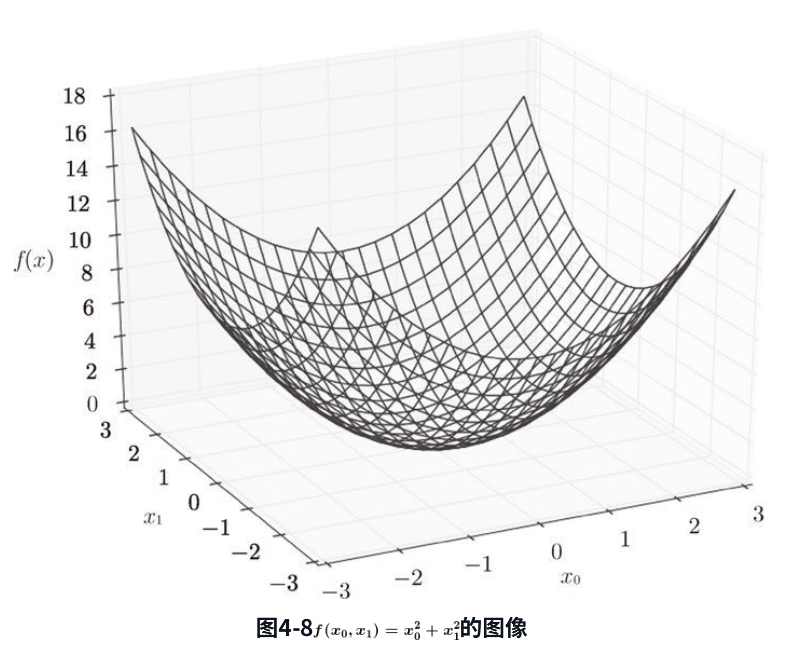
求 x0=3,x1=4 时,关于 x0的偏导数$ \frac{\partial f}{\partial x_0} $。
>>> def function_tmp1(x0):
... return x0*x0 + 4.0**2.0
...
>>> numerical_diff(function_tmp1, 3.0)
6.00000000000378我们定义了一个固定x1= 4的新函数,然后对只有变量 x0 的函数应用了求数值微分的函数。
梯度
对于由全部变量的偏导数汇总而成的向量称为梯度(gradient)。