- 词袋(bag-of-words):是一种表示非结构化文本的方法[插图]。它早在20世纪50年代就被提出,但直到2000年前后才开始流行。
- 工作原理:首先进行分词(tokenization),将将句子拆分成单个词或子词**(词元,token)。在分词之后,我们将每个句子中所有不同的词组合起来,创建一个可用于表示句子的词表(vocabulary)**。
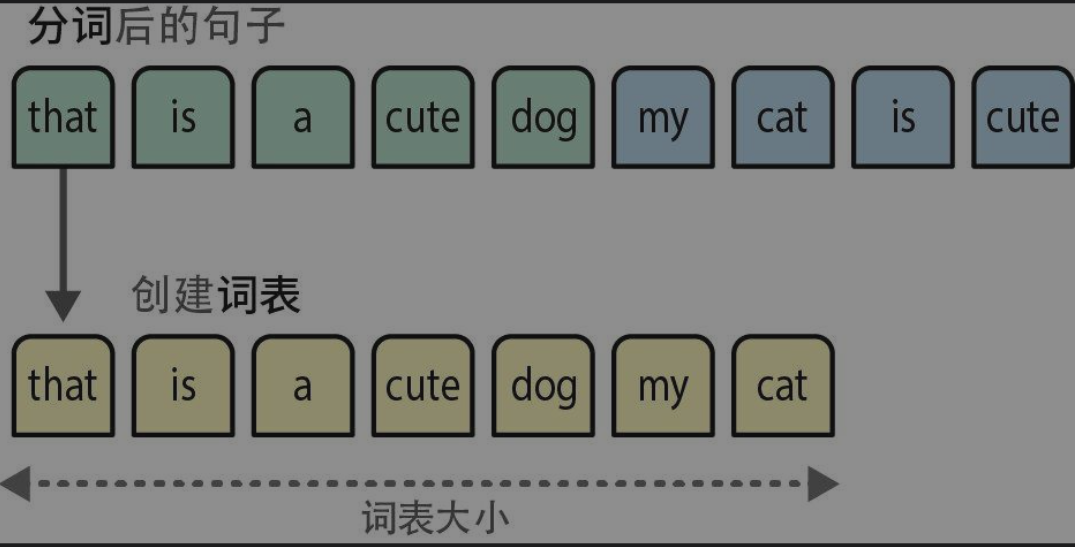
- 词袋忽略了文本的语义特性和含义,仅仅把语言视为一个字面意义上的“词袋”。
- **word2vec(词向量):**利用嵌入(embedding)这个概念来捕捉文本含义。嵌入是数据的向量表示。
- 词嵌入非常有用,因为它使我们能够衡量两个词的语义相似度。

- LLM 由其生成模型本身和其底层的分词器(tokenizer)组成。
- 分词器承担一个类似于“翻译“的工作。
- 没有分词器,模型无法理解输入文本,也无法把生成的词元转回字符串;反之,只有分词器而没有模型,也无法进行任何生成。
Skip to content